The Rhythm of Lyrics
Problem:
Your vocal melodies feel wrong somehow, as if there’s a “conflict” between the rhythm of the melody and the natural flow of the lyrics.
Writing vocal parts is a fundamentally more complicated problem than writing instrumental music because words and sentences have their own implicit rhythm that needs to be consciously considered. Here are some tips for understanding how to get your musical and textual rhythms to work together (or to counter each other, if that’s your intention).
Solution:
Scansion is the study of a text’s inherent rhythm and the marking of each syllable in the text as being either strongly or weakly stressed. We use these stress patterns naturally and unconsciously when speaking and, unless we’re poets, probably never need to give them much thought outside of a musical context.
As an example: Let’s pretend this sentence is a lyric in your song. (Note: Artistically, this is probably not a good idea.) When you read it out loud, you will naturally apply a stress or “accent” to some syllables, while others will be spoken more softly. We’ll mark the strong syllables with a / and the weak ones with a *. (By convention, these stress markings are placed over the first vowel in the syllable.):

Applying these markings can sometimes be subjective. For example, it could be argued that “is” is weakly stressed (although it is probably stressed slightly more than the “a” that follows it). But now that we have a general sense of the inherent stress patterns of the text, we can relate this directly to the inherent stress patterns of musical beats. A couple of general (but by no means universal) rules:
- (Assuming a 4/4 meter), the first and third beats are considered “strong” or “on” beats while the second and fourth are considered “weak” or “off” beats.
- As you subdivide beats into shorter note values such as eighths and sixteenths, the same rule applies. That is, the odd-numbered subdivisions are perceived as stronger than the even-numbered ones.
Placing strong syllables on strong beats and weak syllables on weak beats usually results in a fairly natural-sounding vocal melody, while doing the opposite can often sound forced or stilted. Additionally, you can reinforce these natural alignments further by making stressed syllables louder, higher in pitch, or longer in duration.
Here’s an example of a possible melody for this lyric:
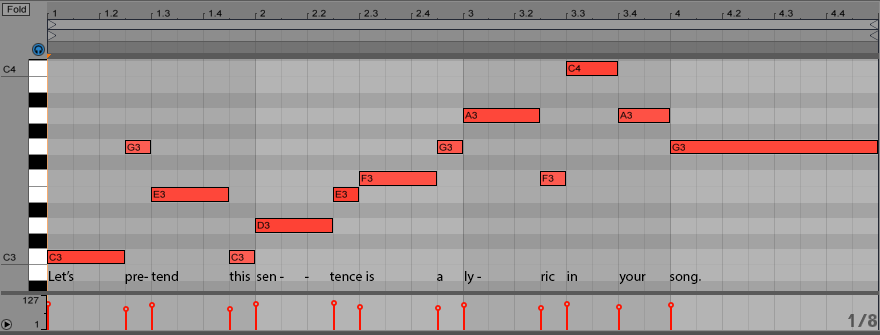
It’s boring, but it “works” according to the scansion rules discussed earlier. Natural text accents occur on strong beat positions and are further emphasized by occurring on notes that last longer, while weakly stressed syllables occur on weak beats and have short durations.
To contrast, let’s take a look at a possible melody that goes against the natural stresses of the lyric:
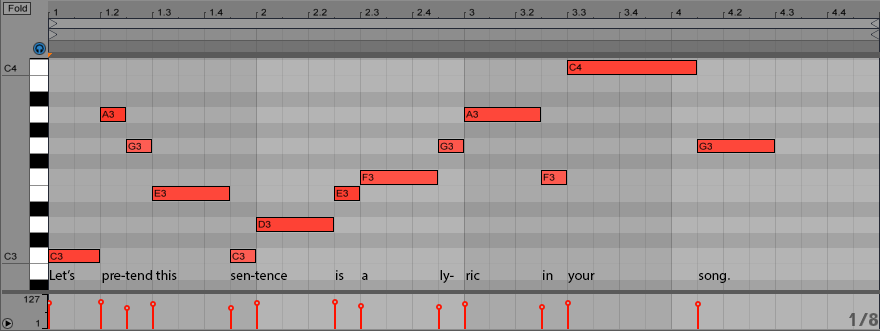
This is nearly identical to the first melody, but with an additional note added on beat two of the first bar in order to shift each syllable to the left. Now we’re breaking all the rules. The weakly stressed syllables happen almost entirely on strong beats and are sustained for long note durations, while the strongly accented syllables are short and on weak beats. This would be both difficult to sing and uncomfortable to listen to.
Although good vocal melodies are often significantly more nuanced and rhythmically intricate than both of these examples, you’ll find that most of the time, good melodies follow the natural patterns of stress in the lyrics. Of course, there are exceptions. A lot of contemporary hip-hop, for example, uses syncopation and unusual stress patterns to go against the rhythm of the text. And it’s always possible to apply more than one syllable of text to a single sustained note or, conversely, sustain a single syllable of text across more than a single pitch. But these are conscious and genre-specific musical decisions. If you find that your own vocal writing tends to feel strained and unnatural, it might be because you’re fighting against how the lyrics want to flow.